



Facebook Reality Labs, научно-исследовательское подразделение компании, возглавляет работу по созданию достаточно реалистичных аватаров виртуальной реальности. Новое исследование группы направлено на поддержку новых выражений лица.

Facebook Reality Labs, научно-исследовательское подразделение компании, возглавляет работу по созданию достаточно реалистичных аватаров виртуальной реальности. Новое исследование группы направлено на поддержку новых выражений лица.
Большинство аватаров, используемых сегодня в виртуальной реальности, скорее мультяшные, чем человеческие, в основном это способ избежать того, когда более «реалистичные» аватары становятся все более визуально отталкивающими по мере приближения, но этого недостаточно для того, чтобы понять, как человек действительно смотрит и двигается.
Проект «Codec Avatar» в Facebook Reality Labs направлен на преодоление эффекта «зловещей долины», используя сочетание машинного обучения и компьютерного зрения для создания гиперреалистичных представлений пользователей. Обучив систему понимать, как выглядит лицо человека, а затем поручив ей воссоздание этого образа на основе данных с камер внутри гарнитуры VR, проект продемонстрировал действительно впечатляющие результаты .
Воссоздание типичных выражений лица с достаточной точностью, чтобы быть убедительным, уже является проблемой, но есть множество крайних случаев, с которыми нужно иметь дело, любой из которых может отбросить всю систему и погрузить аватара обратно в «зловещую долину».
По словам исследователей Facebook, большая проблема заключается в том, что «нецелесообразно иметь единообразную выборку всех возможных [лицевых] выражений», потому что существует просто так много разных способов исказить лицо. В конечном итоге это означает, что в данных примерах системы есть пробел, а это приводит к путанице, когда она видит что-то новое.
Исследователи Ханг Чу, Шугао Ма, Фернандо Де ла Торре, Санья Фидлер и Ясер Шейх предлагают решение в недавно опубликованной исследовательской статье под названием «Выразительное телеприсутствие через модульные аватары кодеков» .
В то время как исходная система аватаров кодеков пытается сопоставить всё выражение лица из своего набора данных с входными данными, которые она видит, система модульных аватаров кодеков разделяет задачу по отдельным чертам лица, таким как каждый глаз и рот, позволяя ей синтезировать наиболее точную позу путем слияния лучшего соответствия из нескольких различных поз в ее данных.
В Modular Codec Avatars модульный кодер сначала извлекает информацию из каждой отдельной камеры, установленной на гарнитуре. За ним следует модульный синтезатор, который оценивает полное выражение лица вместе с его весовыми коэффициентами смешивания на основе информации, извлеченной в той же модульной ветви. Наконец, несколько оценочных 3D-лиц объединяются из разных модулей и смешиваются вместе, чтобы сформировать окончательный результат выражения лица.
Цель состоит в том, чтобы улучшить диапазон выражений, которые могут быть точно представлены без необходимости вводить в систему дополнительные данные для обучения. Можно сказать, что система Modular Codec Avatar разработана для того, чтобы лучше делать выводы о том, как должно выглядеть лицо, по сравнению с исходной системой Codec Avatar, которая больше полагалась на прямое сравнение.
Одним из основных преимуществ этого подхода является улучшение способности системы воссоздавать новые выражения лица, которым она изначально не была обучена, — например, когда люди намеренно искажают свои лица забавными способами, особенно потому, что люди обычно не делают такие лица. Исследователи назвали это конкретное преимущество в своей статье, заявив, что «смешные выражения лиц являются частью социального взаимодействия. Модель Modular Codec Avatar, естественно, может лучше облегчить эту задачу за счет большей выразительности».
Они проверили это, сделав «искусственные» смешные лица путем случайной перетасовки черт лица из совершенно разных поз (например: левый глаз из {позы A}, правый глаз из {позы B} и рот из {позы C}) и посмотрели, сможет ли система дать реалистичные результаты, учитывая неожиданно несходные входные данные.
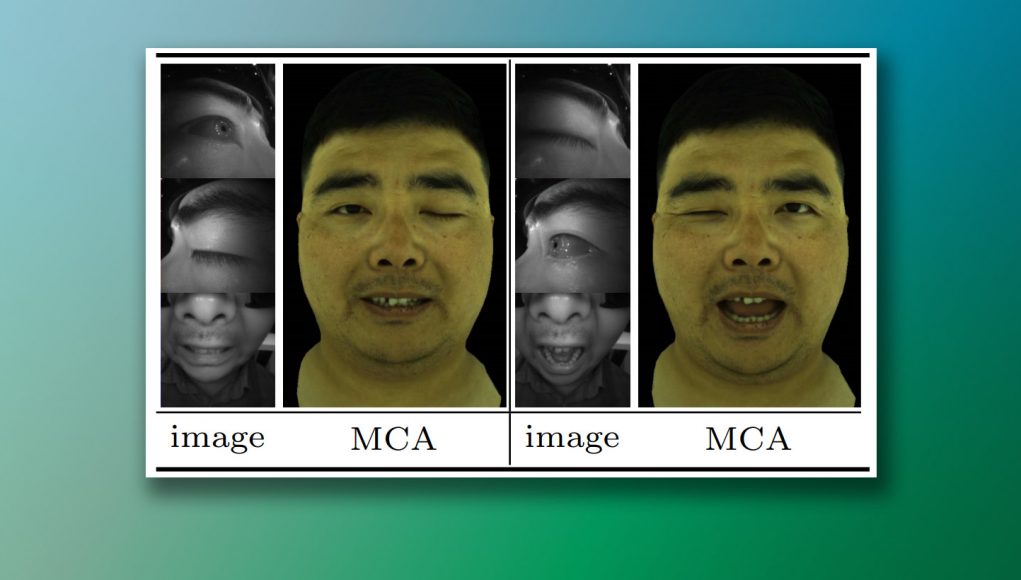
«Можно увидеть [на рисунке выше], что аватары модульных кодеков создают естественные гибкие выражения, хотя такие выражения никогда не встречались целиком в обучающем наборе», — говорят исследователи.
Исследователи обнаружили, что система Modular Codec Avatar не только делает смешные лица, но и улучшает реализм лица, устраняя разницу в позе глаз, присущую ношению гарнитуры.
В практическом виртуальном телеприсутствии мы наблюдаем, как пользователи часто не открывают глаза в полной мере естественным образом. Это может быть связано с давлением мышц от ношения гарнитуры и отображением источников света рядом с глазами. Для решения этой проблемы мы вводим ручку управления усилением глаза.
Это позволяет системе тонко изменять глаза, чтобы они были ближе к тому, как они выглядели бы на самом деле, если бы пользователь не носил гарнитуру.
Хотя идея воссоздания лиц путем объединения элементов из разрозненных фрагментов данных примеров сама по себе не нова, исследователи говорят, что «вместо использования линейных или неглубоких объектов на 3D-сетке [как и предыдущие методы], наши модули происходят в скрытых пространствах, изучаемых глубокими нейронными сетями. Это позволяет захватывать сложные нелинейные эффекты и создавать лицевую анимацию с новым уровнем реализма».
Этот подход также является попыткой сделать такое представление аватара более практичным. Тренировочные данные, необходимые для достижения хороших результатов с помощью Codec Avatars, требуют сначала захвата реального лица пользователя во многих сложных выражениях лица. Аватары модульного кодека достигают аналогичных результатов с большей выразительностью при меньшем количестве обучающих данных.
Пройдет еще некоторое время, прежде чем любой, у кого нет доступа к световой сцене для сканирования лица, сможет быть так точно представлен в виртуальной реальности, но при постоянном прогрессе кажется правдоподобным, что однажды пользователи смогут быстро и легко снимать свою собственную модель лица с помощью приложение для смартфона, а затем загружать её в качестве основы для аватара.



